Ich hatte kürzlich von meiner nicht hunderprozentig zufriedenstellenden Suche nach einer Fuzzy-Search für die Bash geschrieben. Das Problem ist nicht das Herausfiltern an sich, sondern die Gewichtung der Ergebnisse. Als Maß für die Güte eignet sich die Levenshtein-Distanz. Diese zählt die Notwendigen Ersetzungen, Einfügungen und Löschungen, die nötig sind, um String a in String b zu überführen. Je geringer diese sogenannte Distanz, desto ähnlicher sind sich die Strings und desto passender sind sie als Suchergebnis (zumindest in der Theorie).
Meine Suche nach einer einfachen Implementierung, die ich von der Bash aufrufen kann, ist leider erfolglos geblieben. Interessanterweise ist die Implementierung der Levenshtein-Distanz für eine Fuzzy-Search sehr einfach, so dass es sich auch in sperrigem Bash gut umsetzen lässt.
Nur Einfügungen = einfache Levenshtein-Distanz
Die Vereinfachung basiert auf der Tatsache, dass bei meiner Fuzzy-Search nur eingefügt, nie aber ein Zeichen gelöscht oder verändert wird. Suchen wir unscharf nach abc, so ergeben sich beide Strings als Treffer:
cat $file_to_be_filtered
xxxaxxxbxxxcxxx yyyaybcyyy
Im nächsten Schritt schneiden wir alles weg, was nicht benötigt wird, um den String matchen zu lassen (hier muss non-greedy gesucht werden, um den kleinst-möglichen Treffer zu finden):
... | grep -oP .*?a.*?b.*?c.*?
axxxbxxxc aybc
Nun zählen wir die verbliebene Zeichenlänge und ziehen die Länge des Fuzzy-Suchstrings (|abc| = 3) ab und ermitteln somit die Levenshtein-Distanz.
axxxbxxxc # 9 - 3 = 6 aybc # 4 - 3 = 1
Die Länge des Suchstrings ist konstant und hat auf die Ordnung keinen Einfluss. Sie kann in der Implementierung weggelassen werden.
... | awk '{ print length }' | sort | head -1
Implementierung in Bash
Hier mal eine einfache Umsetzung, die eine Datei unscharf durchsucht und die Ergebnisse nach aufsteigender Levenshtein-Distanz ausgibt. Der Algorithmus arbeitet mit einer temporären Datei, da sich diese in meinen Augen sehr viel einfacher bearbeiten lassen als Arrays oder ähnliches. Da die Datei nur virtuell im Arbeitsspeicher angelegt wird, sollte dies aber kein Problem darstellen.
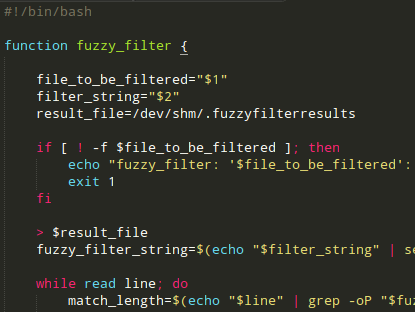
#!/bin/bash
file_to_be_filtered="$1"
filter_string="$2"
# use in-memory directory /dev/shm/
result_file=/dev/shm/.fuzzyfilterresults
if [ ! -f $file_to_be_filtered ]; then
echo "fuzzy_filter: '$file_to_be_filtered': No such file"
exit 1
fi
# empty result file
> $result_file
# replace abc with .*?a.*?b.*?c.*?
# ? triggers non-greedy search in Perl
fuzzy_filter_string=$(echo "$filter_string" | sed 's/./&.*?/g')
while read line; do
# get matches only (grep -o) with Perl syntax (-P)
# replace them by their string length (awk)
# return the smallest number (sort | head -1)
match_length=$(echo "$line" | grep -oP "$fuzzy_filter_string" | awk '{ print length }' | sort | head -1)
# check if variable is a number and not 0
if [ "$match_length" -eq "$match_length" ] 2>/dev/null && [ "$match_length" -gt "0" ]; then
# write number, space and original content into result file
line="$match_length $line"
echo $line >> $result_file
fi
done < "$file_to_be_filtered"
# sort by facing order number
sort $result_file -o $result_file
# cut order number and first space, output the rest
cut -d " " -f 2- $result_file
rm -f $result_file